 neo.js.cn@gmail.com
neo.js.cn@gmail.com
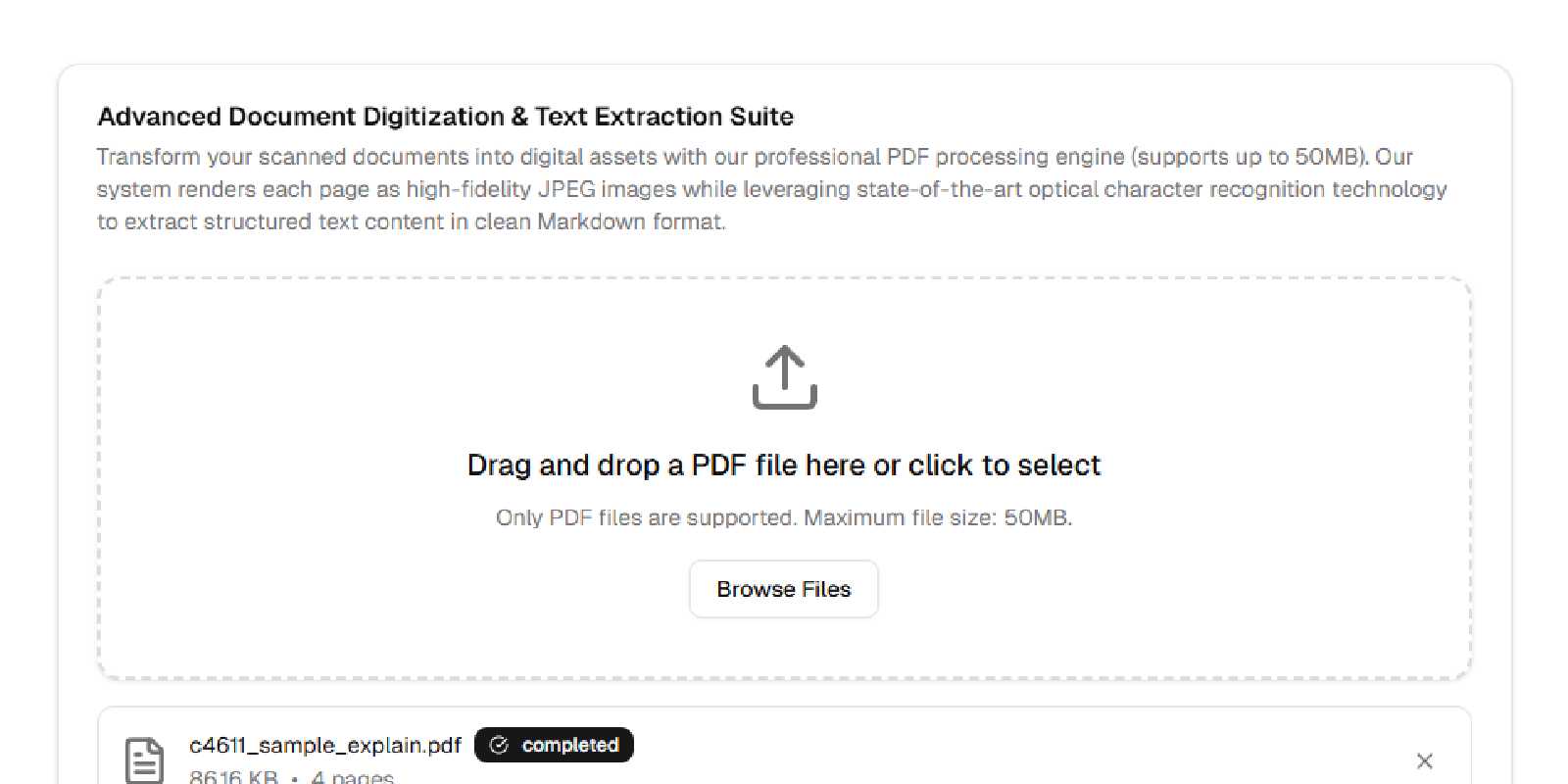
PDFxtract
PDFxtract is a modern web application built with Next.js for processing scanned PDF documents. It is designed to accurately extract text information from images within scanned PDFs using advanced OCR (Optical Character Recognition) technology. Each page of a scanned PDF is automatically converted into a high-quality JPEG image, and AI-powered OCR is applied to precisely recognize and extract the textual content, outputting the results in Markdown format for easy use and further editing.
Features
- Upload PDF files via a simple web interface
- Convert each PDF page to high-quality JPG images
- Preview images online after conversion
- Download all images as a ZIP archive
- Responsive and user-friendly UI
Getting Started
Install dependencies:
npm install # or yarn installStart the development server:
npm run dev # or yarn devOpen your browser and visit http://localhost:3000
Usage
- Click the upload button on the homepage to select a PDF file
- Wait for the conversion to complete; images will be displayed automatically
- Download all images as a ZIP file if needed
Project Structure
app/ # Next.js app directory
api/ # API routes for PDF to JPG and ZIP creation
components/ # React components (PDF uploader, UI elements, etc.)
public/ # Static files and output images
lib/ # Utility functions
Build & Deploy
- Build for production:
npm run build - Start production server:
npm start - Recommended deployment: Vercel
Docker Deployment
Build Image
docker build -t pdfxtract:v0.4 .
Run Container
docker run -d -p 4012:3000 \
-e NODE_ENV=production \
-e NEXT_PUBLIC_GA_ID=<your tag id> \
--name pdfxtract \
pdfxtract:v0.4
Docker Compose Example
version: '3.8'
services:
pdfxtract:
image: pdfxtract:v0.4
ports:
- "4012:3000"
environment:
- NODE_ENV=production
- NEXT_PUBLIC_GA_ID=<your tag id>
restart: unless-stopped
Tech Stack
Contributing
Contributions are welcome! Please open an issue or submit a pull request.
